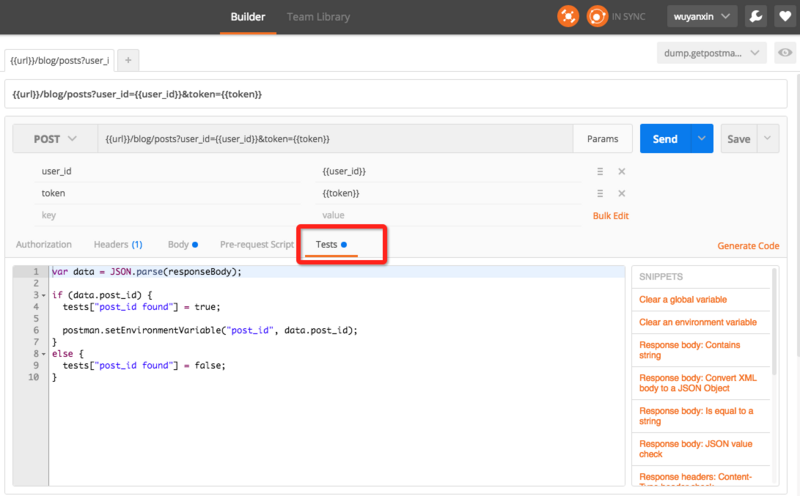
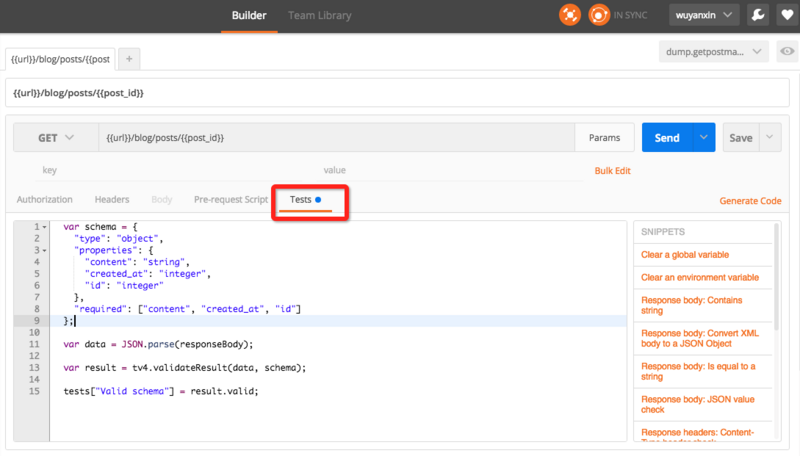
由于第一次接触WebService,对于很多概念不太理解,尤其是看到各个OpenAPI的不同提供方式时,更加疑惑。如google map api采用了AJAX方式,通过javascript提供API,而淘宝TOP则采用直接的HTTP+XML请求方式,最令我疑惑的是教材上讲的WSDL,UDDI从没有在这些API中出现过。现在知道了WebService原来有两种方式,一是SOAP协议方式,在这种方式下需要WSDL,UDDI等,二是REST方式,这种方式根本不需要WSDL,UDDI等。而且REST方式现在看来是更加流行,更有前途的方式。
在SOA的基础技术实现方式中WebService占据了很重要的地位,通常我们提到WebService第一想法就是SOAP消息在各种传输协议上交互。近几年REST的思想伴随着SOA逐渐被大家接受,同时各大网站不断开放API提供给开发者,也激起了REST风格WebService的热潮。
在收到新需求Email之前,我对REST的理解仅仅是通过半懂不懂的看了Fielding的REST博士论文,说实话当时也就是希望了解这么一个新概念,对于其内部的思想只是很肤浅的了解了一下。
ASF的最新需求就是可能需要实现REST风格的WebService集成,因此不得不好好的去看看REST的真正思想含义以及当前各大网站的设计方式。后面所要表述的也是我这个初学者的一些看法和观点,抛砖引玉,希望在我将REST融入到ASF之前能够获得更多的反馈和意见。
SOAP
什么是SOAP,我想不用多说,google一把满眼都是。其实SOAP最早是针对RPC的一种解决方案,简单对象访问协议,很轻量,同时作为应用协议可以基于多种传输协议来传递消息(Http,SMTP等)。但是随着SOAP作为WebService的广泛应用,不断地增加附加的内容,使得现在开发人员觉得SOAP很重,使用门槛很高。在SOAP后续的发展过程中,WS-*一系列协议的制定,增加了SOAP的成熟度,也给SOAP增加了负担。
REST
REST其实并不是什么协议也不是什么标准,而是将Http协议的设计初衷作了诠释,在Http协议被广泛利用的今天,越来越多的是将其作为传输协议,而非原先设计者所考虑的应用协议。SOAP类型的WebService就是最好的例子,SOAP消息完全就是将Http协议作为消息承载,以至于对于Http协议中的各种参数(例如编码,错误码等)都置之不顾。其实,最轻量级的应用协议就是Http协议。Http协议所抽象的get,post,put,delete就好比数据库中最基本的增删改查,而互联网上的各种资源就好比数据库中的记录(可能这么比喻不是很好),对于各种资源的操作最后总是能抽象成为这四种基本操作,在定义了定位资源的规则以后,对于资源的操作通过标准的Http协议就可以实现,开发者也会受益于这种轻量级的协议。
自己理解的将REST的思想归结以下有如下几个关键点:
1.面向资源的接口设计
所有的接口设计都是针对资源来设计的,也就很类似于我们的面向对象和面向过程的设计区别,只不过现在将网络上的操作实体都作为资源来看待,同时URI的设计也是体现了对于资源的定位设计。后面会提到有一些网站的API设计说是REST设计,其实是RPC-REST的混合体,并非是REST的思想。
2.抽象操作为基础的CRUD
这点很简单,Http中的get,put,post,delete分别对应了read,update,create,delete四种操作,如果仅仅是作为对于资源的操作,抽象成为这四种已经足够了,但是对于现在的一些复杂的业务服务接口设计,可能这样的抽象未必能够满足。其实这也在后面的几个网站的API设计中暴露了这样的问题,如果要完全按照REST的思想来设计,那么适用的环境将会有限制,而非放之四海皆准的。
3.Http是应用协议而非传输协议
这点在后面各大网站的API分析中有很明显的体现,其实有些网站已经走到了SOAP的老路上,说是REST的理念设计,其实是作了一套私有的SOAP协议,因此称之为REST风格的自定义SOAP协议。
4.无状态,自包含
这点其实不仅仅是对于REST来说的,作为接口设计都需要能够做到这点,也是作为可扩展和高效性的最基本的保证,就算是使用SOAP的WebService也是一样。
REST vs SOAP
成熟度:
SOAP虽然发展到现在已经脱离了初衷,但是对于异构环境服务发布和调用,以及厂商的支持都已经达到了较为成熟的情况。不同平台,开发语言之间通过SOAP来交互的web service都能够较好的互通(在部分复杂和特殊的参数和返回对象解析上,协议没有作很细致的规定,导致还是需要作部分修正)
REST国外很多大网站都发布了自己的开发API,很多都提供了SOAP和REST两种Web Service,根据调查部分网站的REST风格的使用情况要高于SOAP。但是由于REST只是一种基于Http协议实现资源操作的思想,因此各个网站的REST实现都自有一套,在后面会讲诉各个大网站的REST API的风格。也正是因为这种各自实现的情况,在性能和可用性上会大大高于SOAP发布的web service,但统一通用方面远远不及SOAP。由于这些大网站的SP往往专注于此网站的API开发,因此通用性要求不高。
ASF上考虑发布REST风格的Web Service,可以参考几大网站的设计(兄弟公司的方案就是参考了类似于flickr的设计模式),但是由于没有类似于SOAP的权威性协议作为规范,REST实现的各种协议仅仅只能算是私有协议,当然需要遵循REST的思想,但是这样细节方面有太多没有约束的地方。REST日后的发展所走向规范也会直接影响到这部分的设计是否能够有很好的生命力。
总的来说SOAP在成熟度上优于REST。
效率和易用性:
SOAP协议对于消息体和消息头都有定义,同时消息头的可扩展性为各种互联网的标准提供了扩展的基础,WS-*系列就是较为成功的规范。但是也由于SOAP由于各种需求不断扩充其本身协议的内容,导致在SOAP处理方面的性能有所下降。同时在易用性方面以及学习成本上也有所增加。
REST被人们的重视,其实很大一方面也是因为其高效以及简洁易用的特性。这种高效一方面源于其面向资源接口设计以及操作抽象简化了开发者的不良设计,同时也最大限度的利用了Http最初的应用协议设计理念。同时,在我看来REST还有一个很吸引开发者的就是能够很好的融合当前Web2.0的很多前端技术来提高开发效率。例如很多大型网站开放的REST风格的API都会有多种返回形式,除了传统的xml作为数据承载,还有(JSON,RSS,ATOM)等形式,这对很多网站前端开发人员来说就能够很好的mashup各种资源信息。
因此在效率和易用性上来说,REST更胜一筹。
安全性:
这点其实可以放入到成熟度中,不过在当前的互联网应用和平台开发设计过程中,安全已经被提到了很高的高度,特别是作为外部接口给第三方调用,安全性可能会高过业务逻辑本身。
SOAP在安全方面是通过使用XML-Security和XML-Signature两个规范组成了WS-Security来实现安全控制的,当前已经得到了各个厂商的支持,.net ,php ,java 都已经对其有了很好的支持(虽然在一些细节上还是有不兼容的问题,但是互通基本上是可以的)。
REST没有任何规范对于安全方面作说明,同时现在开放REST风格API的网站主要分成两种,一种是自定义了安全信息封装在消息中(其实这和SOAP没有什么区别),另外一种就是靠硬件SSL来保障,但是这只能够保证点到点的安全,如果是需要多点传输的话SSL就无能为力了。安全这块其实也是一个很大的问题,今年在BEA峰会上看到有演示采用SAML2实现的网站间SSO,其实是直接采用了XML-Security和XML-Signature,效率看起来也不是很高。未来REST规范化和通用化过程中的安全是否也会采用这两种规范,是未知的,但是加入的越多,REST失去它高效性的优势越多。
应用设计与改造:
我们的系统要么就是已经有了那些需要被发布出去的服务,要么就是刚刚设计好的服务,但是开发人员的传统设计思想让REST的形式被接受还需要一点时间。同时在资源型数据服务接口设计上来说按照REST的思想来设计相对来说要容易一些,而对于一些复杂的服务接口来说,可能强要去按照REST的风格来设计会有些牵强。这一点其实可以看看各大网站的接口就可以知道,很多网站还要传入function的名称作为参数,这就明显已经违背了REST本身的设计思路。
而SOAP本身就是面向RPC来设计的,开发人员十分容易接受,所以不存在什么适应的过程。
总的来说,其实还是一个老观念,适合的才是最好的
技术没有好坏,只有是不是合适,一种好的技术和思想被误用了,那么就会得到反效果。REST和SOAP各自都有自己的优点,同时如果在一些场景下如果去改造REST,其实就会走向SOAP(例如安全)。
REST对于资源型服务接口来说很合适,同时特别适合对于效率要求很高,但是对于安全要求不高的场景。而SOAP的成熟性可以给需要提供给多开发语言的,对于安全性要求较高的接口设计带来便利。所以我觉得纯粹说什么设计模式将会占据主导地位没有什么意义,关键还是看应用场景。
同时很重要一点就是不要扭曲了REST现在很多网站都跟风去开发REST风格的接口,其实都是在学其形,不知其心,最后弄得不伦不类,性能上不去,安全又保证不了,徒有一个看似象摸象样的皮囊。
REST设计的几种形式
参看了几个大型网站的REST风格的API设计,这里做一下大致的说明:
FaceBook:
请求消息:
在URI设计上采取了类似于REST的风格。例如对于friends的获取,就定义为friends.get,前面部分作为资源定义,后面是具体的操作,其他的API也是类似,资源+操作,因此就算使用http的get方法都可能作了update的操作,其实已经违背了REST的思想,但是说到,其实那么复杂的业务接口设计下,要通过RUCD来抽象所有的接口基本是不实际的。在URI定义好以后,还有详细的参数定义,包括类型以及是否必选。
响应消息:
有多种方式,XML,JSON。XML有XSD作为参考。有点类似于没有Head的SOAP,只不过这里将原来可以定义在WSDL中的XSD抽取出来了。
Flickr:
请求消息:
http://api.flickr.com/services/rest/?method=flickr.test.echo&name=value
这里就可以很明显看出它所定制的REST请求其实和RPC没有什么太大的区别。
消息返回:
正确处理返回
<?xml version=”1.0″ encoding=”utf-8″ ?>
<rsp stat=”ok”>
[xml-payload-here]
</rsp>
错误处理返回
<?xml version=”1.0″ encoding=”utf-8″ ?>
<rsp stat=”fail”>
<err code=”[error-code]” msg=”[error-message]” />
</rsp>
根据返回可以看出已经违背了REST的思想,还是把Http协议作为传输承载协议,并没有真正意义上使用Http协议作为资源访问和操作协议。
总的来说,只是形式上去模仿REST,自己搞了一套私有协议。
Ebay:
请求消息:
采用xml作为承载,类似于SOAP,不过去除SOAP消息的封装和包头,同时在请求中附加了认证和警告级别等附加信息。
消息返回:
类似于SOAP消息,不过删除了SOAP的封装和包头,同时在返回结构中增加了消息处理结果以及版本等附加信息。
这个很类似于当前Axis2框架的做法,将SOAP精简,同时根据自身需求丰富了安全,事务等协议内容。
Yahoo Maps:
请求消息:
采用REST推荐的方式,URI+Parameters。
返回消息:
<?xml version=”1.0″ encoding=”UTF-8″?>
<ResultSet xmlns:xsi=”http://www.w3.org/2001/XMLSchema-instance”
xmlns=”urn:yahoo:maps”
xsi:schemaLocation=”urn:yahoo:maps http://local.yahooapis.com/MapsService/V1/GeocodeResponse.xsd”>
<Result precision=”address”>
<Latitude>37.416384</Latitude>
<Longitude>-122.024853</Longitude>
<Address>701 FIRST AVE</Address>
<City>SUNNYVALE</City>
<State>CA</State>
<Zip>94089-1019</Zip>
<Country>US</Country>
</Result>
</ResultSet>
SOAP的精简xml返回,其他信息,例如出错码等信息由Http协议头来承载。
YouTube:
请求消息:
可以看到对于资源操作的URI定义也是参数的一部分。
返回消息:
<?xml version=”1.0″ encoding=”utf-8″?>
<ut_response status=”ok”>
<user_profile>
<first_name>YouTube</first_name>
<last_name>User</last_name>
<about_me>YouTube rocks!!</about_me>
<age>30</age>
<video_upload_count>7</video_upload_count>
</user_profile>
</ut_response>
自定义的类SOAP消息。
Amazon:
请求消息:
https://Amazon FPS web service end point/?AWSAccessKeyId=Your AWSAccessKeyId
&Timestamp=[Current timestamp] &Signature=[Signature calculated from hash of Action and Timestamp]
&SignatureVersion=[Signature calculated from hash of Action and Timestamp]
&Version=[Version of the WSDL specified in YYYY-MM-DD format] &Action=[Name of the API]
¶meter1=[Value of the API parameter1] ¶meter2=[Value of the API parameter2]
&…[API parameters and their values]
返回消息:
类似于SOAP的自有协议,消息体中包含了消息状态等附加信息。
总结:
看了上面那么多网站的设计,总结一下主要有这么几种设计方式。
请求消息设计:
1. 基本符合REST标准方式:资源URI定义(资源.操作)+参数。这类设计如果滥用get去处理其他类型的操作,那么和2无异。
2. REST风格非REST思想:资源URI定义+参数(包含操作方法名)。其实就是RPC的REST跟风。
3. 类似于SOAP消息,自定义协议,以xml作为承载。(可扩展,例如鉴权,访问控制等),不过那就好比自己定义了一套SOAP和SOAP extends。大型的有实力的网站有的采取此种做法。
响应消息设计:
1. REST标准方式,将Resource State传输返回给客户端,Http消息作为应用协议而非传输协议
2. 以XML作为消息承载体,Http作为消息传输协议,处理状态自包含。
3. 自定义消息格式,类似于SOAP,提供可扩展部分。
作为遵循REST的理念来看我的选择是响应1和请求1的设计。
REST和ASF的集成
ASF要集成REST就现在来看有两种比较合适的方法。
一.就是采用Axis2的REST实现,这种方式的好处就是开发周期短,容易集成,但是请求和响应的格式无法改变,资源URI设计受限,Axis2的REST其实就是将SOAP消息精简,请求的时候删除了SOAP的头,响应的时候仅仅返回资源信息,如果提供xsd就可以被各种客户端所解析。并非真正的REST。
二.就是采用Restlet开源框架,将Restlet开源框架集成到ASF中,由于Restlet本身就是可内嵌的应用框架,因此集成不成问题,同时Restlet框架只是API结构框架,因此实现和定义完全分开,集成Restlet以后可以自己实现其中的解析引擎也可以采用默认提供的引擎,同时对于内嵌Jetty等多种开源项目的支持,将更多优势融入到了Rest中。看了一下国内也有很多朋友已经关注Restlet开源项目,看了它的架构设计,个人觉得还是比较灵活和紧凑的。
题外话
在写这篇文章以前写了一篇调研报告群发给各个架构师们参考,期待反馈。下午正好和我们的首席架构师聊了一会儿。其实我和他的感觉是一样的,REST是否真的在我们现有的服务框架中需要集成,理解了REST的思想再去看应用场景,那么可以发现如果要完全遵循REST的设计理念来设计接口的话,那么强要去改变现有已经存在的或者还未开发的接口就会落入为了技术而技术,为了潮流而跟风的近地。当然并不否认REST的好,其实我们兄弟公司的一些业务场景有部分的接口十分合适这类设计,面向资源,高效,简洁,易用都能够体现出它的价值。我们将会和我们的兄弟公司合作,也会参考他们的设计理念,在参考当前各个网站的实现情况下,部分的采用这类形式的发布,提供给第三方的ISV,无疑是我现在把REST融入到ASF中最好的理由。
有了需求去做才不会陷入为了技术而技术,毕竟技术是由商业价值驱动的,同样社会上充斥着各种技术的鼓吹,如果稍不留神就会陷入跟风的潮流中。